
SentiLink
Published
September 1, 2020

In September 2019, SentiLink was selected by the Social Security Administration (SSA) to participate in its eCBSV pilot, an automated service that allows permitted entities to validate name, DOB, and SSN combinations against the Numident, the SSA’s database of record for eCBSV. In July 2020, we became the first company to go live with the program. This blog post is the fourth in a series of eCBSV-content, and will provide additional background on a broader whitepaper that we distributed in June.
As one of five service providers chosen by the SSA to participate in the eCBSV pilot, SentiLink wanted to provide an optimal experience for our partners. We have been processing applications for these partners for years, but in the context of eCBSV, there was one big unknown: what would be considered the source of truth for the match? That’s when we discovered the Numident.
The Numident file is the system of record for the SSA’s enumeration data, “enumeration” being the SSA’s term for assigning an individual an SSN. It contains the unique SSN “enumerated” to an individual based on information provided on the original application for Social Security cards, as well as any identity changes related to the SSN over time. Because it is acting as the sole “source of truth” for eCBSV, we looked into the accuracy of the Numident.
At first blush, we had some real concerns. Google “is the Numident accurate” and you’ll find a good deal of sources suggesting Numident errors are alarmingly common. After a lot of research, we finally settled on an analysis conducted by the SSA itself called the Annual Data for Enumeration Accuracy, which seems to be the most up-to-date analysis of the specific Numident error rates relevant for eCBSV. This report details SSN, name, and DOB errors measured annually during the period of 2006 through 2015 and lays the foundation for SentiLink’s eCBSV error rate analysis. It wasn’t perfect, but it does help us understand errors in the SSA’s Numident system that most closely resemble what eCBSV pilot participants will experience.
After additional investigations into the SSA’s enumeration practices, we determined that the organic error rate of the SSA Numident is anywhere between 0.05–2.13%. That’s a pretty large range, and we wanted to be able to provide a more definite estimate for our partners. However, the data from the Annual Data for Enumeration Accuracy analysis didn’t give us that chance.
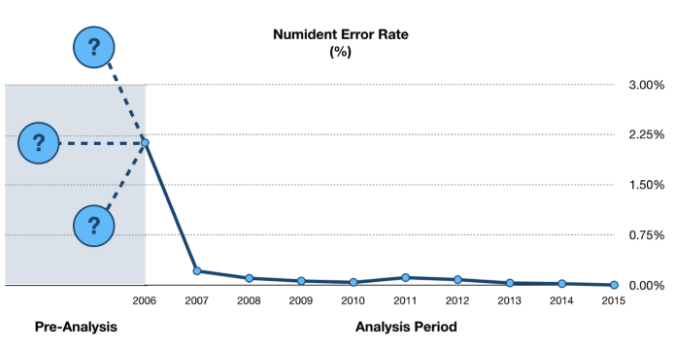
As you can see from the graph above, the overall Numident error rate drops significantly from 2.3% in 2006 to below 0.5% in 2007, and then bounces along until it settles on a 0% error rate. Considering this anomaly, it’s a bit of a head-scratcher why the SSA didn’t analyze the years preceding 2006. From the data, there was no way for us to determine if prior years were better, worse, or much worse than what was shown in 2006, so we had to guesstimate a large range for errors in the Numident.
It’s an even more unpleasant (but educational) picture when you break down SSN error rates by the way they were enumerated. As you can see below, error rates from enumeration at Field Offices measured at roughly 8% in 2006.
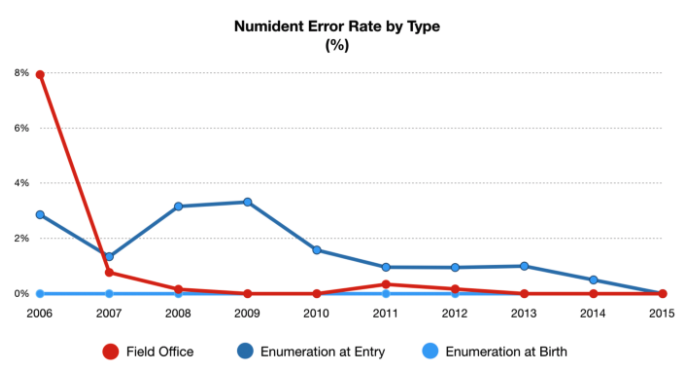
That’s a high error rate that we assume was borne out of less-than-adequate quality checks in place at that time. Consider this: SSA field offices received on average 170,000 visits per day for the last 10 years. That’s about 40 million individual in-person visits every year, many of which result in SSA employees accessing online systems and making manual changes to consumer records in the Numident. Without tight quality controls in place for manual keying, those annual visits could create a lot of human error. This anomaly also leads us to the conclusion that older Americans are more likely to have errors in their SSN Numident although again, we can’t measure the level of error rates.
The chart above also shows error rates for Enumeration at Birth — a program introduced in 1985 by the SSA that allows birthing centers and hospitals to register a newborn for a SSN at time of birth — and Enumeration at Entry, which refers to the issuance of SSNs to immigrants who are lawfully admitted as permitted residents. As you can see from the chart, Enumeration at Birth and Enumeration at Entry error rates trend down to 0% over time.
We are not sure if it was OIG oversight, SSA programmatic changes, or better Field Office training that led to decreases in the error rates. Whatever the case, if the analysis had been started a year later, we would have had a vastly different picture of SSNs that were enumerated prior to 2006. An equally important but unanswer question is, “Has the SSA been able to make accuracy improvements retroactively to records enumerated prior to 2006?” Because we don’t know this answer, again we have to provide a broad range for potential inaccuracies in the Numident.
What does this mean to participants of the eCBSV pilot program?
Simply put, at least 1 in 200 applications to the eCBSV will generate a false mismatch stemming from a Numident error. That is, a real applicant will be told that their record cannot be found in the Numident because of a Numident specific error, leading to potential consumer frustration and lower customer conversion. As an industry, we should treat each applicant as if they might be that 1 in 200 and help them understand the value of the eCBSV program as well as how to correct their Numident record.
Each of us should have processes in place to direct consumers to their local field office if they feel they are being wrongly identified as a potential synthetic fraud. Additionally, consumers can request a copy of their information in the Numident by sending an application and $22 to the FOIA, or by setting up a my Social Security account online.
There are other error types that will need further explanation or remediation. These additional error types are discussed in the broader whitepaper, which we developed with our eCBSV partners and their consumers in mind.
Download our broader eCBSV white paper and we’ll invite you to a video conference call SentiLink will be hosting in mid-to-late September where we will be reviewing our findings from the first days of processing eCBSV.
Subscribe
Share
Related Content

Blog article
April 3, 2024
Tips from a Fraud Fighter for Spotting Assumed Identity Abuse
Read article
Blog article
February 29, 2024
Reducing Complexity in Model Risk Management with Attributes
Read article
Blog article
January 18, 2024
What criminals pay to buy stolen identities and tips to keep yours safe
Read article